I am a researcher at the Shanghai AI Laboratory , where I collaborate with a team on advanced AI research. Concurrently, I am a Ph.D. student at The University of Sydney, working under the guidance of Wanli Ouyang on AI topics. I previously earned my B.E. degree from Zhejiang University and had the privilege of graduating with honors from Chu Kochen Honors College. During my time there, I had the valuable experience of working with Xiaowei Zhou at the ZJU-3DV Lab, whom I also regarded as another advisor of mine.
My research interests focus on building a capable super-intelligent system that can solve real-world perception, reasoning, understanding, and action problems, essentially pursuing AGI(Artificial General Intelligence). Given the difficulty of this goal, my current research primarily addresses the spatial intelligence: Enabling a general intelligence system to fully understand the 3D world (together with Tong He). I am still in the early stages of this long-term pursuit. Due to the divergence in my research interests, I also explore several directions out of curiosity and enjoyment. More details can be found below.
Prospective interns: We are looking for self-motivated research interns. If you are interested in working with us, please drop an email. We highly value strong motivation and coding ability.
Depth Any Video introduces a scalable synthetic data pipeline, capturing 40,000 video clips from diverse games, and leverages powerful priors of generative video diffusion models to advance video depth estimation. By incorporating rotary position encoding, flow matching, and a mixed-duration training strategy, it robustly handles varying video lengths and frame rates. Additionally, a novel depth interpolation method enables high-resolution depth inference, achieving superior spatial accuracy and temporal consistency over previous models.
Neurips
NeuRodin: A Two-stage Framework for High-Fidelity Neural Surface Reconstruction
Signed Distance Function (SDF)-based volume rendering has demonstrated significant capabilities in surface reconstruction. Although promising, SDF-based methods often fail to capture detailed geometric structures, resulting in visible defects. By comparing SDF-based volume rendering to density-based volume rendering, we identify two main factors within the SDF-based approach that degrade surface quality: SDF-to-density representation and geometric regularization. These factors introduce challenges that hinder the optimization of the SDF field. To address these issues, we introduce NeuRodin, a novel two-stage neural surface reconstruction framework that not only achieves high-fidelity surface reconstruction but also retains the flexible optimization characteristics of density-based methods. NeuRodin incorporates innovative strategies that facilitate transformation of arbitrary topologies and reduce artifacts associated with density bias. Extensive evaluations on the Tanks and Temples and ScanNet++ datasets demonstrate the superiority of NeuRodin, showing strong reconstruction capabilities for both indoor and outdoor environments using solely posed RGB captures. All codes and models will be made public upon acceptance.
ECCV
Agent3D-Zero: An Agent for Zero-shot 3D Understanding
Sha Zhang, Di Huang, Jiajun Deng, Shixiang Tang, Wanli Ouyang, Tong He, and Yanyong Zhang
The ability to understand and reason the 3D real world is a crucial milestone towards artificial general intelligence. The current common practice is to finetune Large Language Models (LLMs) with 3D data and texts to enable 3D understanding. Despite their effectiveness, these approaches are inherently limited by the scale and diversity of the available 3D data. Alternatively, in this work, we introduce Agent3D-Zero, an innovative 3D-aware agent framework addressing the 3D scene understanding in a zero-shot manner. The essence of our approach centers on reconceptualizing the challenge of 3D scene perception as a process of understanding and synthesizing insights from multiple images, inspired by how our human beings attempt to understand 3D scenes. By consolidating this idea, we propose a novel way to make use of a Large Visual Language Model (VLM) via actively selecting and analyzing a series of viewpoints for 3D understanding. Specifically, given an input 3D scene, Agent3D-Zero first processes a bird’s-eye view image with custom-designed visual prompts, then iteratively chooses the next viewpoints to observe and summarize the underlying knowledge. A distinctive advantage of Agent3D-Zero is the introduction of novel visual prompts, which significantly unleash the VLMs’ ability to identify the most informative viewpoints and thus facilitate observing 3D scenes. Extensive experiments demonstrate the effectiveness of the proposed framework in understanding diverse and previously unseen 3D environments.
CVPR
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
In the context of autonomous driving, the significance of effective feature learning is widely acknowledged. While conventional 3D self-supervised pre-training methods have shown widespread success, most methods follow the ideas originally designed for 2D images. In this paper, we present UniPAD, a novel self-supervised learning paradigm applying 3D volumetric differentiable rendering. UniPAD implicitly encodes 3D space, facilitating the reconstruction of continuous 3D shape structures and the intricate appearance characteristics of their 2D projections. The flexibility of our method enables seamless integration into both 2D and 3D frameworks, enabling a more holistic comprehension of the scenes. We manifest the feasibility and effectiveness of UniPAD by conducting extensive experiments on various downstream 3D tasks. Our method significantly improves lidar-, camera-, and lidar-camera-based baseline by 9.1, 7.7, and 6.9 NDS, respectively. Notably, our pre-training pipeline achieves 73.2 NDS for 3D object detection and 79.4 mIoU for 3D semantic segmentation on the nuScenes validation set, achieving state-of-the-art results in comparison with previous methods.
arXiv
PonderV2: Pave the Way for 3D Foundataion Model with A Universal Pre-training Paradigm
In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method.
ICCV
Ponder: Point cloud pre-training via neural rendering
We propose a novel approach to self-supervised learning of point cloud representations by differentiable neural rendering. Motivated by the fact that informative point cloud features should be able to encode rich geometry and appearance cues and render realistic images, we train a point-cloud encoder within a devised point-based neural renderer by comparing the rendered images with real images on massive RGB-D data. The learned point-cloud encoder can be easily integrated into various downstream tasks, including not only high-level tasks like 3D detection and segmentation, but low-level tasks like 3D reconstruction and image synthesis. Extensive experiments on various tasks demonstrate the superiority of our approach compared to existing pre-training methods.
Recently, 3D assets created via reconstruction and generation have matched the quality of manually crafted assets, highlighting their potential for replacement. However, this potential is largely unrealized because these assets always need to be converted to meshes for 3D industry applications, and the meshes produced by current mesh extraction methods are significantly inferior to Artist-Created Meshes (AMs), i.e., meshes created by human artists. Specifically, current mesh extraction methods rely on dense faces and ignore geometric features, leading to inefficiencies, complicated post-processing, and lower representation quality. To address these issues, we introduce MeshAnything, a model that treats mesh extraction as a generation problem, producing AMs aligned with specified shapes. By converting 3D assets in any 3D representation into AMs, MeshAnything can be integrated with various 3D asset production methods, thereby enhancing their application across the 3D industry. The architecture of MeshAnything comprises a VQ-VAE and a shape-conditioned decoder-only transformer. We first learn a mesh vocabulary using the VQ-VAE, then train the shape-conditioned decoder-only transformer on this vocabulary for shape-conditioned autoregressive mesh generation. Our extensive experiments show that our method generates AMs with hundreds of times fewer faces, significantly improving storage, rendering, and simulation efficiencies, while achieving precision comparable to previous methods.
ECCV
GVGEN:Text-to-3D Generation with Volumetric Representation
Xianglong He*, Junyi Chen*, Sida Peng, Di Huang, Yangguang Li, Xiaoshui Huang, Chun Yuan, Wanli Ouyang, and Tong He
In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities. To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form GaussianVolume. This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of GaussianVolume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline. It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed (∼7 seconds), effectively striking a balance between quality and efficiency.
ICML
FiT: Flexible Vision Transformer for Diffusion Model
Nature is infinitely resolution-free. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain. To overcome this limitation, we present the Flexible Vision Transformer (FiT), a transformer architecture specifically designed for generating images with unrestricted resolutions and aspect ratios. Unlike traditional methods that perceive images as static-resolution grids, FiT conceptualizes images as sequences of dynamically-sized tokens. This perspective enables a flexible training strategy that effortlessly adapts to diverse aspect ratios during both training and inference phases, thus promoting resolution generalization and eliminating biases induced by image cropping. Enhanced by a meticulously adjusted network structure and the integration of training-free extrapolation techniques, FiT exhibits remarkable flexibility in resolution extrapolation generation. Comprehensive experiments demonstrate the exceptional performance of FiT across a broad range of resolutions, showcasing its effectiveness both within and beyond its training resolution distribution.
NeurIPS
Seeing is not always believing: Benchmarking Human and Model Perception of AI-Generated Images
Photos serve as a way for humans to record what they experience in their daily lives, and they are often regarded as trustworthy sources of information. However, there is a growing concern that the advancement of artificial intelligence (AI) technology may produce fake photos, which can create confusion and diminish trust in photographs. This study aims to comprehensively evaluate agents for distinguishing state-of-the-art AI-generated visual content. Our study benchmarks both human capability and cutting-edge fake image detection AI algorithms, using a newly collected large-scale fake image dataset Fake2M. In our human perception evaluation, titled HPBench, we discovered that humans struggle significantly to distinguish real photos from AI-generated ones, with a misclassification rate of 38.7%. Along with this, we conduct the model capability of AI-Generated images detection evaluation MPBench and the top-performing model from MPBench achieves a 13% failure rate under the same setting used in the human evaluation. We hope that our study can raise awareness of the potential risks of AI-generated images and facilitate further research to prevent the spread of false information.
In this paper, we introduce a novel path to general human motion generation by focusing on 2D space. Traditional methods have primarily generated human motions in 3D, which, while detailed and realistic, are often limited by the scope of available 3D motion data in terms of both the size and the diversity. To address these limitations, we exploit extensive availability of 2D motion data. We present Holistic-Motion2D, the first comprehensive and large-scale benchmark for 2D whole-body motion generation, which includes over 1M in-the-wild motion sequences, each paired with high-quality whole-body/partial pose annotations and textual descriptions. Notably, Holistic-Motion2D is ten times larger than the previously largest 3D motion dataset. We also introduce a baseline method, featuring innovative whole-body part-aware attention and confidence-aware modeling techniques, tailored for 2D Text-drivEN whole-boDy motion genERation, namely Tender. Extensive experiments demonstrate the effectiveness of Holistic-Motion2D and Tender in generating expressive, diverse, and realistic human motions. We also highlight the utility of 2D motion for various downstream applications and its potential for lifting to 3D motion.
AAAI
MotionGPT: Finetuned LLMs are General-Purpose Motion Generators
Yaqi Zhang, Di Huang, Bin Liu, Shixiang Tang, Yan Lu, Lu Chen, Lei Bai, Qi Chu, Nenghai Yu, and Wanli Ouyang
Generating realistic human motion from given action descriptions has experienced significant advancements because of the emerging requirement of digital humans. While recent works have achieved impressive results in generating motion directly from textual action descriptions, they often support only a single modality of the control signal, which limits their application in the real digital human industry. This paper presents a Motion General-Purpose generaTor (MotionGPT) that can use multimodal control signals, e.g., text and single-frame poses, for generating consecutive human motions by treating multimodal signals as special input tokens in large language models (LLMs). Specifically, we first quantize multimodal control signals into discrete codes and then formulate them in a unified prompt instruction to ask the LLMs to generate the motion answer. Our MotionGPT demonstrates a unified human motion generation model with multimodal control signals by tuning a mere 0.4% of LLM parameters. To the best of our knowledge, MotionGPT is the first method to generate human motion by multimodal control signals, which we hope can shed light on this new direction.

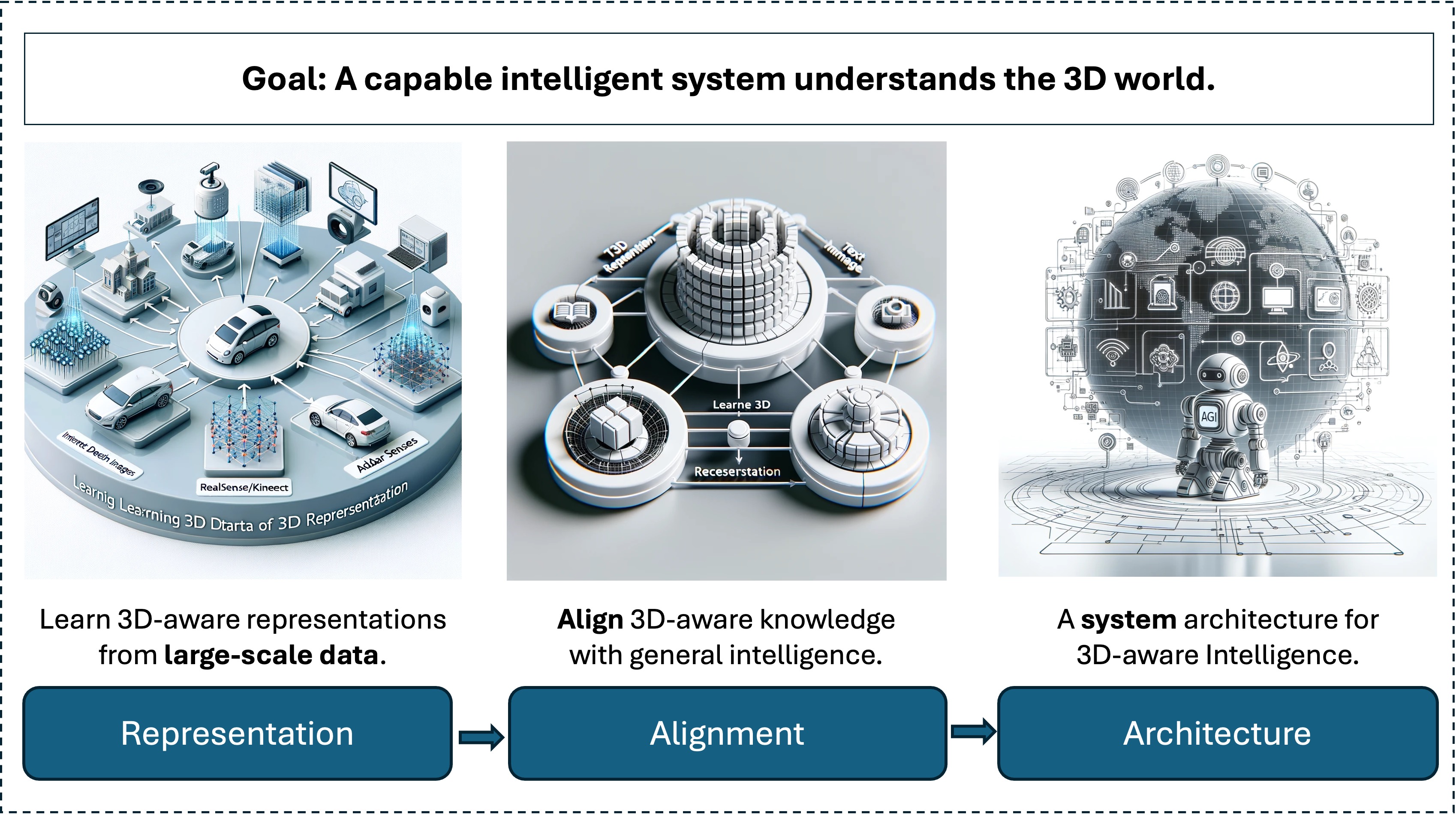 To empower foundation models with the abilities of percepting, understanding, and acting in the 3D real-world; Images are generated by OpenAI DALLE 3.
To empower foundation models with the abilities of percepting, understanding, and acting in the 3D real-world; Images are generated by OpenAI DALLE 3. 










